Book Scanning
We are holding ourselves back from a better future. Why are ebooks not completely backwards-compatible with every paper version ever printed? Why are ebooks not as advanced in typography? Why can't one buy an electronic copy of a book, with all the editor and layout pleasantries? Why are people allowed to re-sell physical books, but not electronic copies? When copyright terms became near-infinite, what economies are being squashed out that might be good for society?
Think of these questions while I outline my process for digitizing paper books. It is possible to have a better-than-paper experience with no restrictions. There are many options for scanning books, and almost all of them are expensive, bulky, and inaccessible. The only one that cuts through that (pun intended) is by using a guillotine to cut the spine. This turns the pages into loose-leaf, and the pages may be loaded into a document feed scanner (ADF).
Books are really important to me. I grew up collecting all kinds, with the highest interest in the most-obscure ones. For years, I wondered about how best to interact with the medium. Trying different marginalia, ranging from "writing in the margins" through "highlighting on a Kobo", I must now say: most ebooks suck. They are rubbish, and lack a deeper vision for this medium. The only usable ebooks are scanned copies because marginalia stays in-place, they are typeset, and are suitable for reproduction.
Contents
Hardware
I do my scanning with a Fujitsu fi-4120c2, which is a USB 2.0 600 DPI duplex feed scanner. It had perfect support with SANE, the most-popular free scanning software, so I purchased one from eBay for about $30. I use this scanner directly with FreeBSD. One thing I do regularly is to clean the sensor glass, which sometimes gets gummy from glue left on cover pages. I've also replaced the two rubber pads that separate pages; these were available on eBay for $5.
Software
The scanner plugs into my computer with USB. From my terminal, I run some commands to scan various kinds of material. For paperback books, I start with the front cover, in-color, at 300 DPI. The rest of the pages are usually monotone. Occasionally, where there are pictures I will use grayscale or color.
I'll describe processing further in a later section, but it basically by stabilizing the pages. Text is cut out, identified for location/features, and re-paged according to precise margins. Optional masks of gray/color areas are identified. OCR is applied. Pages are re-aggregated into a single .pdf, and finally metadata is added such as publishing details and chapter markers. A .djvu derives from the .pdf.
Feeding the Machine
The guillotine I use is located at my nearest UPS store. Because I had a lot of books, and this store was a franchise where the owner was working, we struck a deal on the price (he didn't have a SKU for the service). I get even further discounts when I pre-measure my books. They set the width on their guillotine, the book is inserted, and the spine is chopped off. Measure well, because sometimes there is residual glue stuck between the pages, obstructing page separation. It doesn't hurt to cut more off than you think, without getting into ink, because the text may later be re-paged with precise margins.

Before loading the pages into the scanner, I fan them out a few times to be sure there are no stuck pages. Then, I fan them vertically (so it forms a knife-shape into the scanner) with my leading page most prominent. Using this method I never get paper jams.
I wrote this script for scanning. Use it like: w=130 h=210 t=128 scan.sh front color 300. For paperbacks, I typically test the threshold value against text and two-tone images, and if it looks good in the sample I follow through with this process:
- Front cover, Color, 300 DPI
- Back of front cover, BW, 600 DPI
- Ordinary pages, BW, 600 DPI
- Multi-tone pages, Gray, 600 DPI
- Graphics, Color 300 DPI
- Front of back cover, BW, 600 DPI
- Back cover, Color, 300 DPI
The result is a directory containing only PNG images. At this point, I make an archive of the pages so I have a backup if something goes wrong during processing.
Image Processing
Using a very simple script, I re-page (crop and flush the border). It's just a little pnmtools mixed in with imagemagick. If I ever find the time, I intend to write a more-nuanced program that will statistically average the text borders, look at line positions, and actually re-page the text so the lines of paragraphs are colinear between pages, giving a nice experience. For now, I'm cheap and time's s'pensive. Below are before and after images of this process.

Metadata
Page sizing
It is important to embed the proper page sizes into the PDF because it impacts how it gets rendered in a client. Without this, most clients default to 72px per inch, and with high-resolution PDFs the window instantaneously maximizes. Todo: write here about using ghostscript to set page resolution with -gWIDTHPXxHEIGHTPX -rRESPX.
OCR
It is easy to convert these images to PDF, with a text overlay, using tesseract. Using GNU Parallel dramatically speeds processing by running one job per CPU core (use it wherever you can).
\ls *.png | parallel tesseract {} ../crop/{/.} --dpi 600 -l eng pdf
I always do OCR as my last step before uniting the individual pages into a single PDF because sometimes other PDF processors are poorly-written and can mess it up.
Bookmarking and Extras
I've been meaning to get around to automatic chapter detection, but for now I use a good old spreadsheet to record the chapter placements. First, I measure the distance between Page 1 and the file index (e.g. p. 1 is 26.png so the difference is 25). Then, add that offset to the page numbers in the Table of Contents. So, if Chapter 3 starts on Page 43 in the ToC, that means the bookmark should appear on Page 68 (43+25).
Eventually, you'll need to write (or generate) a text document that looks like this. In this example, I have also added a Title, Subject, Author, ISBN number, and bookmarks at different indentation levels. This can be applied with pdftk like so: pdftk merged.pdf update_info bookmarks.txt output mergedwithbookmarks.pdf.
Output and Reading Experience
Here is a sample of a textbook scanned using a modified process, whereby grayscale and color areas are masked, seperated into individually-compressed layers, and recomposited. This gives a great level of detail with a medium file size, which works well for converting into very-compressible .djvu files.
Todo: add another sample of paperback book
Comparision of file formats
PDF is great for most readers, but some people prefer smaller file sizes. For those cases, I recommend DJVU because it is Free and offers great compression. Lower file sizes are important because page turns are generally faster, and more of the library can be loaded on a device.
Devices
The reMarkable Tablet and SuperNote devices are great, Linux-running tablets with Wacom pen input. They make it a pleasure to read and write. I use a reMarkable for all my reading, which, at 10 inches, is a nice compromise between full-letter size (~13 inches) and smaller A6 card size.
Appendix A: Topology Mapping with Microsoft Kinect
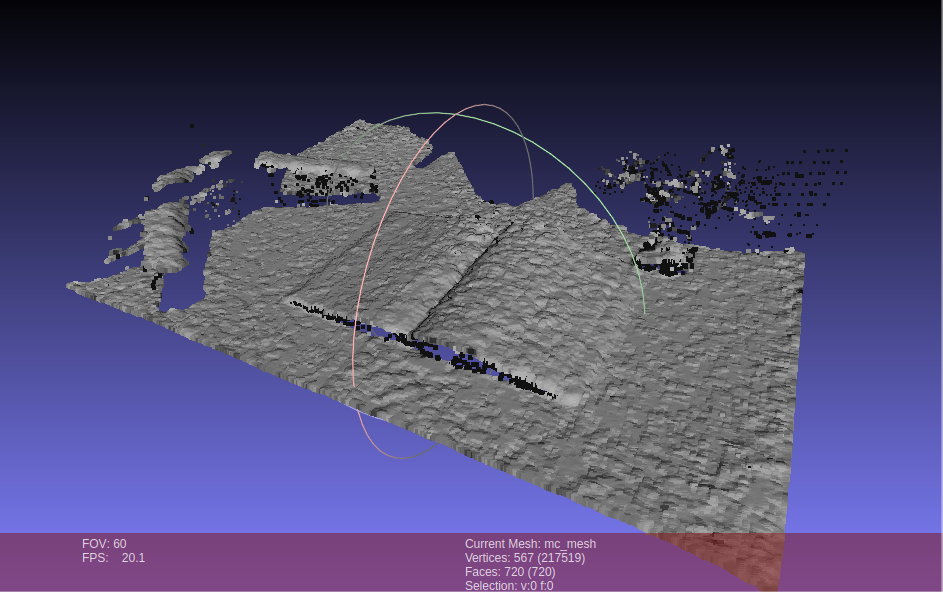 Before I decided to cut the spines off my books, I investigated
using a Kinect to make a 3D point-cloud of the book's pages,
then use that to dewarp a high-resolution image. I did some
searching, but only a couple
people
played around with the idea...eight years ago! After
investigating this myself, I determined it was a fool's path.
Before I decided to cut the spines off my books, I investigated
using a Kinect to make a 3D point-cloud of the book's pages,
then use that to dewarp a high-resolution image. I did some
searching, but only a couple
people
played around with the idea...eight years ago! After
investigating this myself, I determined it was a fool's path.
First, there's a problem with the software. It is difficult to source the software that communicates and controls a Microsoft Xbox 360 Kinect, and there is another version (my kind) that was made for PC, with a different model number. I was able to overcome this limitation by using Robot Operating System (ROS).
Second, even though I was now able to obtain the point cloud data, there was a problem: it was extremely noisy! To add, the depth resolution of the Kinect wasn't that great, either. At this point, I thought it was a neat idea, but didn't have the patience to continue pursuing it. There are better ideas, like shining a LASER line at an angle on the page, which could give a simpler, better measure. I ended up chopping my books, because I no longer saw it as destructive; done right, it was a transformation that made them more-valuable, not less.
Shown above, is a point cloud in MeshLab. At left is my rolling chair, center the book, and upper-right is a crumpled tissue.
